|
|
Post by B+ on Nov 27, 2019 1:05:35 GMT
Hi Rod,
Definitely do get better results with 1000 tests not 10000 tests, so what is happening, blowing a rnd fuse with so many calls?
Hi John,
I haven't replaced rnd with shuffle, in fact I use it for shuffling.
With shuffle, I am only shuffling 10 digits and drawing first... wait 2nd digit, d(1) is 2nd in 0 based array.. anyway any digit has 1/10 of a chance for being drawn so if the digit < 5 like 0, 1, 2, 3, 4 then B = -1 else B = 1 for 5, 6, 7, 8, 9 and then B is added to BTOTAL.
BTOTAL Should alternate back and forth between being positive or negative but it seems to lean very much towards the negative.
|
|
|
|
Post by B+ on Nov 27, 2019 1:45:12 GMT
OK so something happens to RND if you call it too much???
Here is 10 trials of 500 sums of 1 or -1 and raw rnd delivers a positive sum for 25% of seeds .01 to .99 and with shuffle 47% seeds give a positive sum.
'OK 10 times of 500 tests so RND wont blow a fuse
dim d(9)
for i = 0 to 9 : d(i) = i : next
for testWithShuffle = 0 to 1
for seed = .01 to 1 step .01
scan
print seed;",";
POS = 0 : NEG = 0
randomize seed '.3, .4 least neg so far whew .5!
FOR A = 1 TO 10
scan
FOR X=1 TO 500
scan
if testWithShuffle = 1 then
call shuffle
if d(1) < 5 then B = -1 else B = 1
else
if rnd(0) < .5 then B = -1 else B = 1
end if
'print B;
BTOTAL = BTOTAL + B
NEXT X
'PRINT BTOTAL
if BTOTAL < 0 then NEG = NEG + 1 else POS = POS + 1
BTOTAL = 0
'zero total here if you don't want it to accumulate
NEXT A
'print "Negative totals ";NEG;" Positive totals ";POS
if POS > NEG then print "Positive outcome with seed ";seed : ptotal = ptotal + 1
next
print : print
print "Of 99 seeds = ";ptotal;" had positive totals of 10 sums of 500 additions."
print :print
ptotal = 0
next
sub shuffle ' shuffle the digits Fisher-Yates algo
for i = 9 to 1 step -1
r = int(rnd(0) * (i + 1))
t = d(i) : d(i) = d(r) : d(r) = t
next
end sub
|
|
|
|
Post by Rod on Nov 27, 2019 12:56:14 GMT
Ok, we are drifting away from the initial question.
B+ consider this simpler code.
for m= 1 to 20
for n = 1 to 100000
scan
if rnd(0)>.497 then pos=pos+1 else neg=neg+1
next
print "Neg :";neg,"Pos :";pos,
if pos>neg then print "Positive" else print
neg=0
pos=0
next
Why have I used .497? Well the comparison of floating points is problematic and doing 100000 comparisons accumulates errors. The rnd() result is floating point and will have garbage at the end. The float you code to compare it against 0.5 will have garbage at the end so to say is float x > < or = to float y is simply accumulating garbage.
I choose .497 to get an even spread of positives and negatives, If I changed the number of comparisons I would probably need to adjust that value .
So I think there is less wrong with rnd() per say than the code we all write to test it. I don't think the seed has much influence over the result either, it is just a way of starting a predictable sequence.
I don't understand the series test discussed in the initial question, we should see what coding errors we have there.
Anatoly, you did some good work showing the very slight bias rnd() has, can you find that again. I just want to show folks what the bias we talk about actually is.
|
|
|
|
Post by B+ on Nov 27, 2019 15:12:59 GMT
Hi Rod, I don't understand where this accumulation is taking place from comparisons of floats??? It is not being saved in any variables. Isn't (rnd(0) > .497) a simple Boolean, 0 or 1? Show me the garbage!  We can go back to INT(RND * 3) - 1 if you prefer, I thought (rnd < .5) was simpler. I was comparing different seeds to see how the distribution of what should be a 50/50 outcome was turning out. I was using seeds because the results can be easily replicated. Nobody can say, "Oh you just were unlucky with your run.", which is likely when using RND. You have to admit using .497 is fixing something off with rnd, oh hey you are doing 100,000 sums? |
|
|
|
Post by B+ on Nov 27, 2019 16:41:59 GMT
Hi Davey,
My prediction formula for sequence lengths = nTrials * (1/2^(nRepeats + 1) eg for 0 repeats the chance is 50/50 or will get in 1/2 your number of trials. 1/4 of trials will have 1 repeat digit 1/8 of trials will have 2 repeat digits and so on... which sums to 1 * nTrials.
Here is my code test:
'Counting sequence lengths - B+ 2019-11-27
nTests = 1000
while seed < 100
seed = seed + .01 'set new seed to keep fresh
randomize seed '<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< for results that can be replicated
while i < 100
scan
r = rnd(0) ' run out rnd a little to get past worse of negative parts?
i = i + 1
wend
dim rCnt(21) 'reset
for test = 1 to 1000
repeats = 0 'reset
if (rnd(0) < .497) then leadoff = 0 else leadoff = 1
if (rnd(0) < .497) then follow = 0 else follow = 1
'print leadoff; follow;
while follow = leadoff
scan
repeats = repeats + 1
if (rnd(0) < .497) then follow = 0 else follow = 1
'print follow;
wend
'print " repeats = ";repeats
if repeats < 21 then
rCnt(repeats) = rCnt(repeats) + 1
else
rCnt(21) = rCnt(21) + 1
end if
next
print: Print
Print "(Seed = ";seed;") For ";nTests;" tests the series lengths break down is:"
for i = 0 to 21
print "N Repeats = ";i;" Count = "; rCnt(i); " compare to nTests * 1/2^(repeats + 1) = ";nTests * 1/2^(i+1)
next
input ".... press enter to continue ";w$
wend
EDIT: rnd(0) < .497 gives us a better split between +/- 1 or heads/tails (we think).
|
|
|
|
Post by tenochtitlanuk on Nov 27, 2019 17:23:26 GMT
I threw 600000 zeros or ones and drew a graphic, coded red/blue and also drew a self-scaling graph to show how often I got one of them ( 0 or 1) and the next was different; how often I got two ( 00 or 11) then the next was different, etc. Looks how I'd expect. May give you some ideas. It's always interesting seeing people actually investigating unexpected results rather than throwing their hands in the air and giving up. Keep us informed of further results! 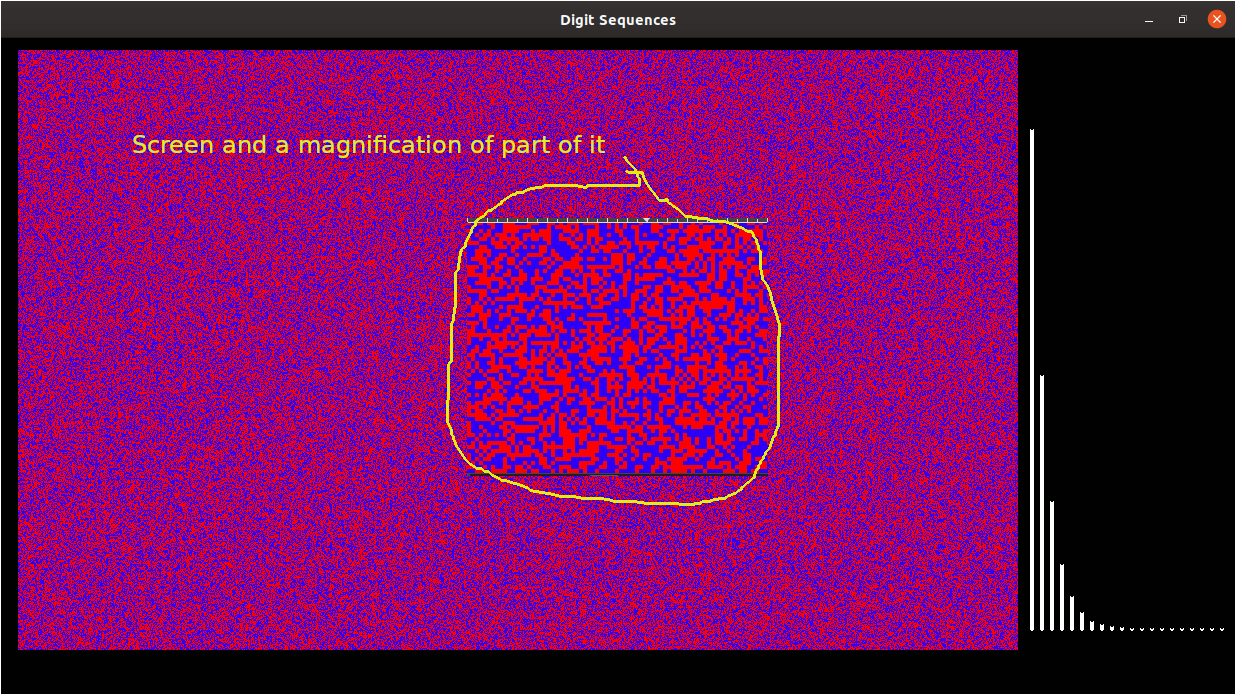 Note the histogram bars show as i/2, 1/4, 18 etc as expected.. Some of my analysis of JB/LB rnd() is on my website. More incliding statistical tests was on the old lost forum. LB code
nomainwin
dim bins( 40)
WindowWidth =1200
WindowHeight = 610
open "Digit Sequences" for graphics_nsb as #wg
#wg "trapclose quit"
#wg "fill black; down ; flush"
previous =int( rnd( 0) *2)
state =previous
runlength =1
binMax =1
for a = 1 to 600
scan
for x =1 to 1000
scan
b = int( rnd( 0) *2)
if b <>previous then bins( runlength) =bins( runlength) +1: previous =b: runlength =1 else runlength =runlength +1
if b = 0 then #wg "color blue"
if b = 1 then #wg "color red"
#wg "down ; set "; x +15; " "; a +10; " up"
previous =b
next x
for k =1 to 20
if binMax <bins( k) then binMax =bins( k)
next k
for k =1 to 20
#wg "color white ; size 4"
#wg "up ; goto "; 1020 +k *10; " 590 "
#wg "down ; goto "; 1020 +k *10; " "; 589 -bins( k) *500 /binMax
#wg "color black"
#wg " goto "; 1020 +k *10; " 0"
#wg "up"
#wg "size 1"
next k
next a
#wg "flush ; getbmp scr 1 1 1200 610"
bmpsave "scr", "sequences.bmp"
wait
sub quit h$
close #h$
end
end sub
|
|
|
|
Post by Rod on Nov 27, 2019 19:40:01 GMT
@ B+
"I don't understand where this accumulation is taking place "
a float is never actually .5 it is always .5000000xxxxxx so only those greater than .5000000xxxx are deemed positive. That's why you get so many negative outcomes. Those on the cusp are skewed negative.
The error is not about rnd() its about float v float.
|
|
|
|
Post by Rod on Nov 27, 2019 20:29:42 GMT
If you are still interested and have not gone off to watch tv or play cards or whatever then study Johns code. He uses int() possibly avoiding the float trap? Put in counters to sum positive results 1 and negative results 0. Its still skewed! But from the pixel image and the chart it looks spot on. It looks completely random and the series distribution is exactly what everyone would expect. So what is skewed? The numbers of each color of pixel, you would expect them to be balanced at 600000 tries, 300000 of each color.
What do I think is the problem? How we measure what rnd() is doing. "b = int( rnd( 0) *2))". Because rnd(0) is a float and because int() is comparing a float we get the "epsilion" skew.
This code uses three variations of an epsilion value, the middle one should give the best split of 0/1, the first more negative and the last more positive. Note that you cannot see the variation in the pixel image because the effect is so small, neither does it budge the series chart by a pixel
'nomainwin
dim bins( 40)
WindowWidth =1200
WindowHeight = 610
open "Digit Sequences" for graphics_nsb as #wg
#wg "trapclose quit"
#wg "fill black; down ; flush"
previous =int( rnd( 0) *2)
state =previous
runlength =1
binMax =1
for a = 1 to 600
scan
if a<200 then epsilion=.01
if a>=200 and a<400 then epsilion=.02
if a>=400 and a<600 then epsilion=.03
for x =1 to 1000
scan
b = int( rnd( 0) *2+epsilion)
if b=0 then neg=neg+1
if b=1 then pos=pos+1
if b <>previous then bins( runlength) =bins( runlength) +1: previous =b: runlength =1 else runlength =runlength +1
if b = 0 then #wg "color blue"
if b = 1 then #wg "color red"
#wg "down ; set "; x +15; " "; a +10; " up"
previous =b
next x
for k =1 to 20
if binMax <bins( k) then binMax =bins( k)
next k
for k =1 to 20
#wg "color white ; size 4"
#wg "up ; goto "; 1020 +k *10; " 590 "
#wg "down ; goto "; 1020 +k *10; " "; 589 -bins( k) *500 /binMax
#wg "color black"
#wg " goto "; 1020 +k *10; " 0"
#wg "up"
#wg "size 1"
next k
if a=200 then print neg,pos :neg=0 :pos=0
if a=400 then print neg,pos :neg=0 :pos=0
next a
print neg,pos
#wg "flush ; getbmp scr 1 1 1200 610"
bmpsave "scr", "sequences.bmp"
wait
sub quit h$
close #h$
end
end sub
'Test the random number generator to see if it can draw
'uniformly random dots!
WindowWidth = 410
WindowHeight = 440
open "random generator test" for graphics_nsb as #draw
print #draw, "trapclose [quit]"
print #draw, "down ; size 2"
for x = 1 to 50000
print #draw, "place "; int(rnd(1)*400); " "; int(rnd(1)*400)
print #draw, "go 1"
next x
wait
[quit]
close #draw
end
You are of course entitled to your own views and opinions, so far this is the only explanation that works for me.
|
|
|
|
Post by B+ on Nov 27, 2019 21:42:12 GMT
OK .497 does give nice split of seeds for Randomize for 1000 sums of plus and minus 1.
That is better than the slower shuffle method for huge amount of calculations, so I will adjust code counting sequences to using .497 to split.
|
|
|
|
Post by daveylibra on Nov 28, 2019 0:02:39 GMT
I don't understand the series test discussed in the initial question, we should see what coding errors we have there. Well, I just generate a a long string of numbers - eg 0,1,1,0,0,0,1,1,1,0,0,1,0,1,0,1,1,1,1,0,0,......... The string should be random. In this example we have - One 0. That's a series length 1, then 2 1s. A series length 2, then 3 0s. A series length 3, then 3 1s. A series length 3 etc... Probability theory says (amount of series length 1) > (amount series of all other lengths). I was just trying to test this out. |
|
|
|
Post by B+ on Nov 28, 2019 1:54:48 GMT
Yeah each series length has half the likely-hood of the previous with the first = 1/2,
so 1/2 + 1/4 + 1/8 + ... = 1 the probability of any length.
John has it illustrated in his graphic.(The histogram bar chart on the right of the red and blue spec modern art work.)
|
|
|
|
Post by Rod on Nov 28, 2019 13:34:25 GMT
Looking at the original code I would look for the series runs this way. You get a straight forwards distribution as you would expect to see. However when you compare the count of series of length one to the count of series greater than one the bias creeps back in.
Without the epsilon adjustment you will skew to negative pushing more 0s into the mix and altering the distribution. With epsilon it hangs together and single series are just more prevalent than all others. So matching the theory!
DIM N(10000)
DIM TOTAL(20)
FOR X=1 TO 10000
N(X) = INT(RND(0)*2+.01)
NEXT X
X=1
WHILE X<10000
N=N(X)
COUNT=0
WHILE N=N(X) and X<10000
COUNT=COUNT+1
X=X+1
WEND
TOTAL(COUNT)=TOTAL(COUNT)+1
WEND
FOR N= 1 to 20
PRINT N,TOTAL(N)
NEXT
FOR N= 2 to 20
TOT=TOT+TOTAL(N)
NEXT
PRINT
PRINT "Total of length 1 ";TOTAL(1)
PRINT "Total of length >1 ";TOT
|
|
|
|
Post by B+ on Nov 28, 2019 15:43:31 GMT
Oh I was missing a crucial point, given a string of length n of 0's and 1's... that's different than predicting lengths of series. So this accumulation accounting is saying .5 is more than .5 so rnd < .5 + something is coming out true even with rnd > .5 but still less than . 5 and some junk? So what would be wrong if we compare int(10 * rnd(0)) < 5, all integers, with the junk at the ends of floats truncated? I don't like this epsilon stuff it is too easy to fudge figures until they do what you want.  for seed = .01 to 1 step .01
randomize seed
DIM N(10000)
DIM TOTAL(20)
FOR X=1 TO 10000 'VVVV INT truncates all the junk so integer versus integer comparison VVVV
if int(10*rnd(0)) < 5 then N(X) = 0 else N(X) = 1
NEXT X
X=1
WHILE X<10000
N=N(X)
COUNT=0
WHILE N=N(X) and X<10000
COUNT=COUNT+1
X=X+1
WEND
if COUNT < 20 then
TOTAL(COUNT)=TOTAL(COUNT)+1
else
TOTAL(20)=TOTAL(20)+1
end if
WEND
FOR N= 1 to 20
PRINT N,TOTAL(N)
NEXT
TOT = 0
FOR N= 2 to 20
TOT=TOT+TOTAL(N)
NEXT
PRINT
PRINT "Seed: ";seed
PRINT "Total of length 1 ";TOTAL(1)
PRINT "Total of length >1 ";TOT
if TOTAL(1) > TOT then L1 = L1 + 1 else LX = LX + 1
next
print "Of ";L1 + LX;" seed tests:"
print "Times Total of Length 1 was greater than Total of all the other Lengths = ";L1
print "Times the Total of all the other lengths was >= Total of length 1 = ";LX
Results you can replicate yourself: Same code tested in another Basic for N length =10000  I bet you would get better results with Liberty as well. BTW the numbers do rise for series length 1 from low length strings to higher, in powers of 10, 10,000 was when the curve changed in favor of series length 1. So in coin tossing game, if you want to win money betting on series 1, you better agree to pretty long strings ahead of time. |
|
|
|
Post by Rod on Nov 28, 2019 20:08:17 GMT
B+ Int() hmmm it rounds down does it not? So you lose some of your rnd() value. My point is that float v float and int() all introduce measurement errors. If it was clearly 1 or 0 we would have far less issues with rnd() But it isn’t a clean measure it is a dirty measure and it can be compounded by multiple iterations. 10*rnd(0) does not dirty the amount but int() does. So your new measure is cleaner than past measures.
The issue about floats is pretty widespread and well documented. All software using the floating point processor has the same issue. Epsilon is the standard technique for assisting comparisons. A float is held equal if it is more than the value les epsilon and less than the value plus epsilon.
Int() has always rounded down and lost precision.
|
|
|
|
Post by B+ on Nov 28, 2019 20:31:49 GMT
Hi Rod,
INT truncates equally no discrimination, hi or lo, so everything past 0.xxxx is 0 as everything past 9.xxxx is 9
That leaves 10 possible integers: 5 before 5 = 0,1,2,3,4 and 5 after = 5,6,7,8,9 we compare integer versus integer no floats so no junk getting in way.
It should be 50/50.
|
|









